
https://arxiv.org/abs/2208.08340
Introduction
マルチモーダルのやつ。画像について、文字で○○してとNLPに解析させていくように、両方のタスクを使う。
CLIPという既存手法は、cosine類似度で画像とテキストがどれだけ似ているかを、比較行列を作って判別する。これがマルチモーダルで一番よく使われているもの。
LLMをうまく訓練してそれでいろんなタスク=下流タスクをうまく行わせるのが難点であり、解決法の1つとしてはPrompt Engineeringであった。
- Image Class Tokenとは、生成するクラスを指示する情報。
- Image Embeddingとは、画像を埋め込み表現にしたもの。
- Visual Promptとは、似てそうな画像の情報?書いてないんだよな。
Method
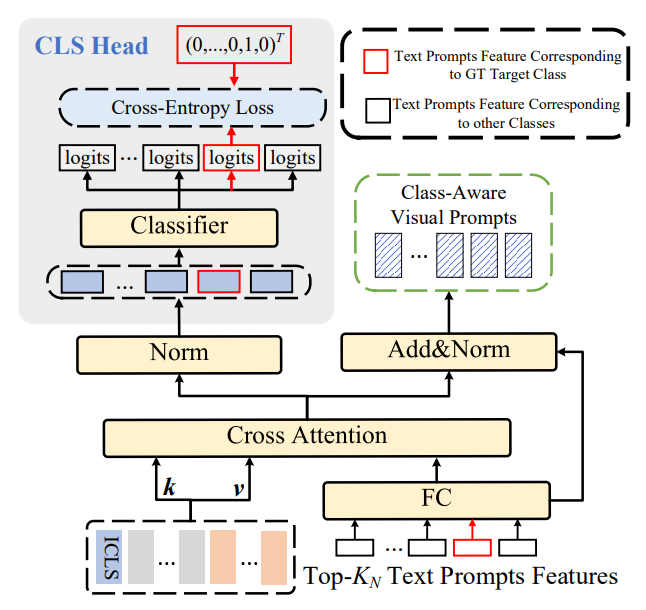
上の図のModuleはCAVPTというモジュールで、目標はTransformerに入れるいい感じのVisual+Text Promptを合わせたものを作りたい。
- Vision Promptは左側で、key, valueを提供。
- ICLSはImage Class Tokenである。
- Text Promptは右側で、queryを提供。
- 与えられたBatchに合致するだろう確率高いもの上位個選択されている。Text Promptはクラス(「犬」、「猫」etc)のembeddingと、Text Promptのembeddingそのものである。
- Text Promptは、自動で生成したEmbedding。クラスの説明文っぽいEmbeddingを人間が考えるのはあほらしいじゃないですか?
- Cross Attentionした後にLayer Normalizationをする。右側はresnetの要領で、text promptから直接入れたものも加算。すると、各Visual Promptにtext promptを付加したのがClass-Aware Visual Promptであり、モジュールが出力するもの。
- Cross Attentionしたものの左側はLayer Normalizationだけして、ひとまずここで正解ラベルとの損失を計算する。そして、ここでBack Propagationを行う対象の1つ。
- たぶん、CLSでまずCross-Attentionがいいものになるように覚えさせたいから、浅い層でもう損失を計算している。早めにCross-Attentionの学習をさせて、モジュールが出力するものを良くする。その結果Transformerの学習を良くしている。
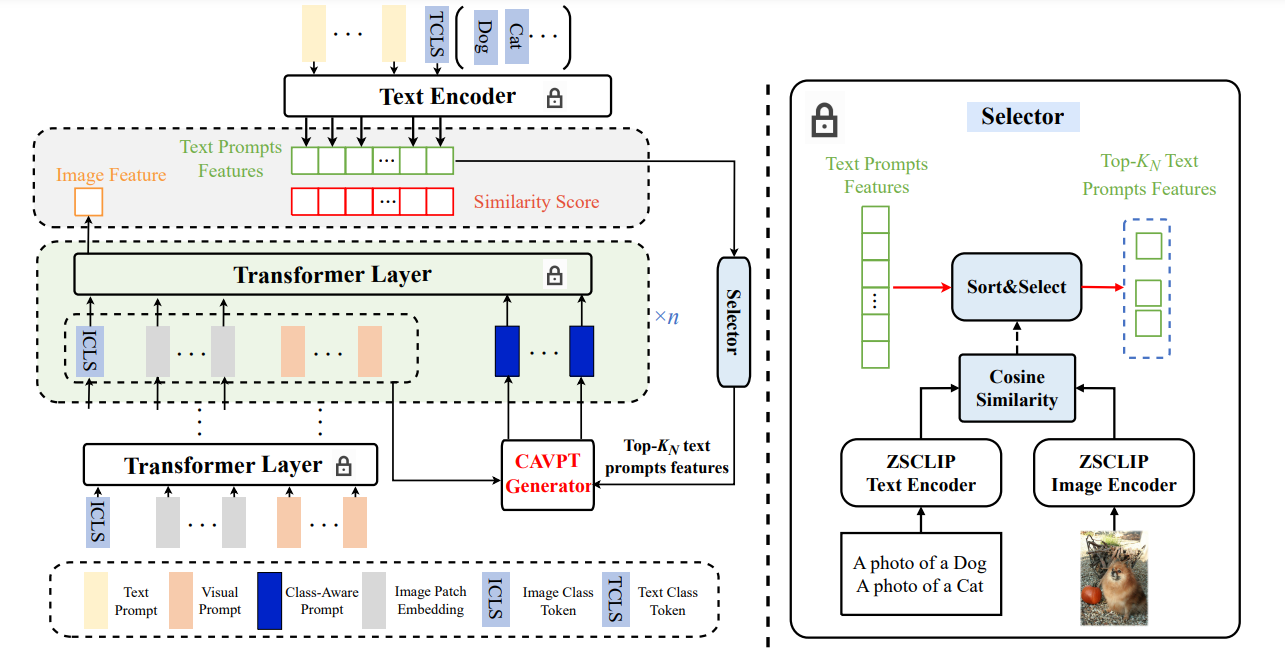
こちらの流れは本筋。
- まずTransformerにVisual Prompt, Image Embedding, Image Class Tokenを入れて埋め込み表演を生成する。
- そこから、Text Promptとの合わせたものを先ほどのCAVPTから得て、Transformerを何層か繰り返す。
- CAVPTの訓練には、先ほども言うようにTopのクラスを使っているが、最終的な比較は全部のクラスとやっている。
- 最後に得たImage FeatureでText Encoderと比較学習を行う。